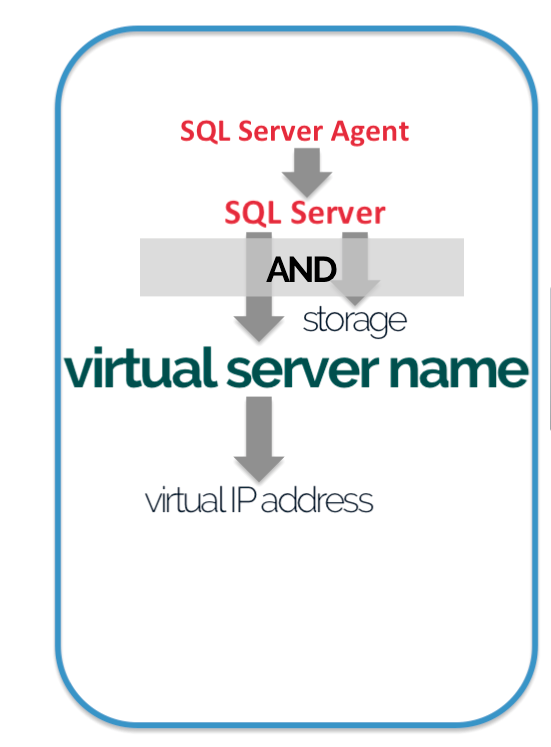
One of the demos that I show when I talk about AND dependencies in a Windows Server Failover Cluster is moving a SQL Server resource group (or role as of Windows Server 2012 and higher) to a different cluster node.
During the failover, I highlight that the SQL Server cluster resource will not come online until both the network name (virtual server name) and the shared disks resources come online – hence the concept of the AND logic dependency. Refer to the picture above for reference. Because the node that runs the SQL Server cluster resource also owns the shared disk resource, the cluster has to release the ownership – be it via intentional or accidental failover – before any of the cluster nodes can take ownership of the disk. The amount of time it takes to bring the SQL Server cluster resource online is partially dependent on the amount of time it takes to unmount the disk on the original node and remount it to the target node. That also means that if the storage subsystem becomes the bottleneck of this unmount/remount process, the SQL Server instance will take longer to bring online and impact availability. Wouldn’t it be nice if we could eliminate the unmount/remount process during the failover to reduce downtime?
Enter Cluster Shared Volumes (CSV). This feature was introduced in Windows Server 2008 R2 primarily for use with the Hyper-V role. The idea behind it is to provide a shared disk that is made available for read and write operations by all nodes within a Windows Server Failover Cluster, a true shared disk in its real sense. We still need to use a shared disk for the cluster but, instead of using it in a traditional way, we convert it to a cluster shared volume.
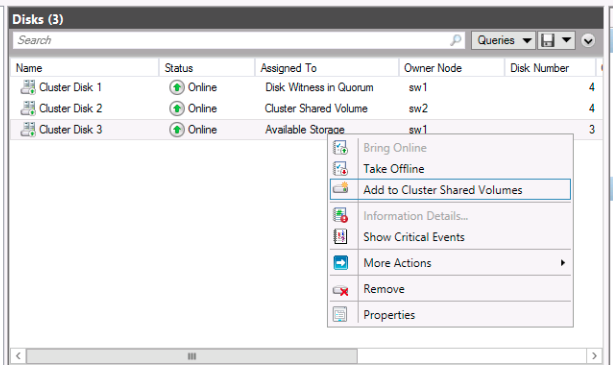
What does it mean to us as SQL Server DBAs? Well, for one, SQL Server 2014 introduced support for CSVs whether you’re running it on Windows Server 2008 R2 or Windows Server 2012. There are a couple of benefits that this feature provides.
- Reduces downtime. Since the SQL Server clustered resource no longer depends on the shared storage to come online (it is still dependent on its existence since all your database files are stored there,) failover will be a lot faster, hence, reducing downtime. Initially, I thought that the shared disks are still owned exclusively by the node currently running the SQL Server resource and only the I/O operations are coordinated by the cluster via the CSV. To verify, I opened up the dependency report.
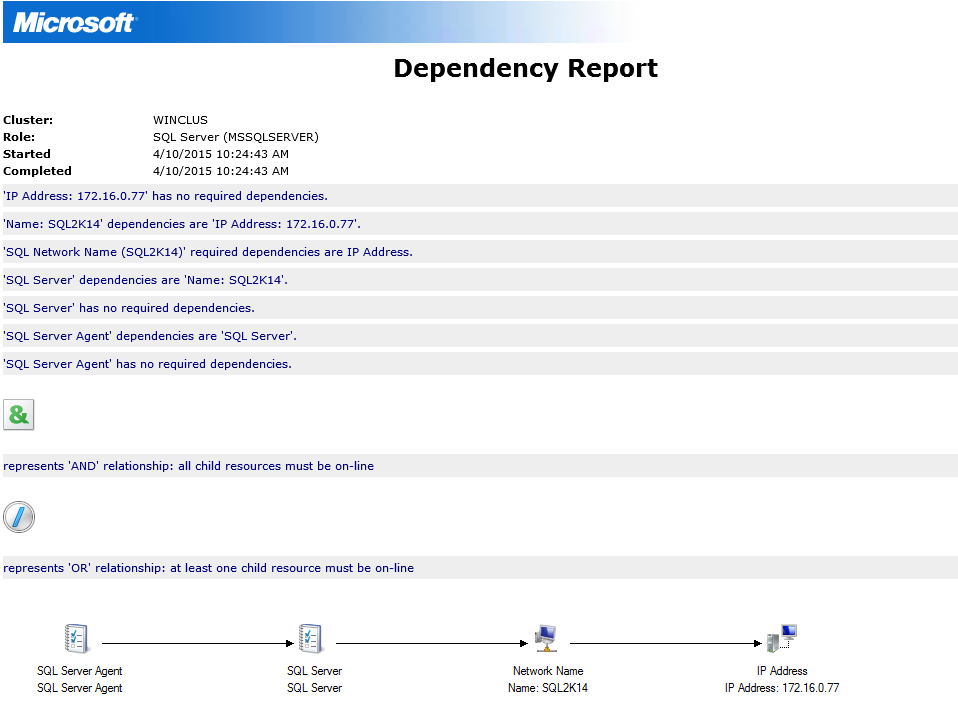 Notice that the SQL Server clustered resource no longer has a dependency on a shared disk for it to come online. As I mentioned, SQL Server is still dependent on the shared disk because that’s where all of your databases are stored. But at least it is no longer dependent on how long it takes to unmount and remount those shared disk for it to come online.
Notice that the SQL Server clustered resource no longer has a dependency on a shared disk for it to come online. As I mentioned, SQL Server is still dependent on the shared disk because that’s where all of your databases are stored. But at least it is no longer dependent on how long it takes to unmount and remount those shared disk for it to come online. - Increased resiliency and reliability. Because we now have multiple paths to the shared disk, if we lose connectivity from the node running the clustered resource, say from a bad cable or a misbehaving firmware, the cluster can then use the other paths available to the shared disk without having to failover the resource group – again, another benefit to reducing downtime. This doesn’t mean that you can just ignore any issues with your underlying storage when it occurs. You still need to address it when it happens, like scheduling a failover during low transactional activity instead of immediately, to achieve service level agreements.
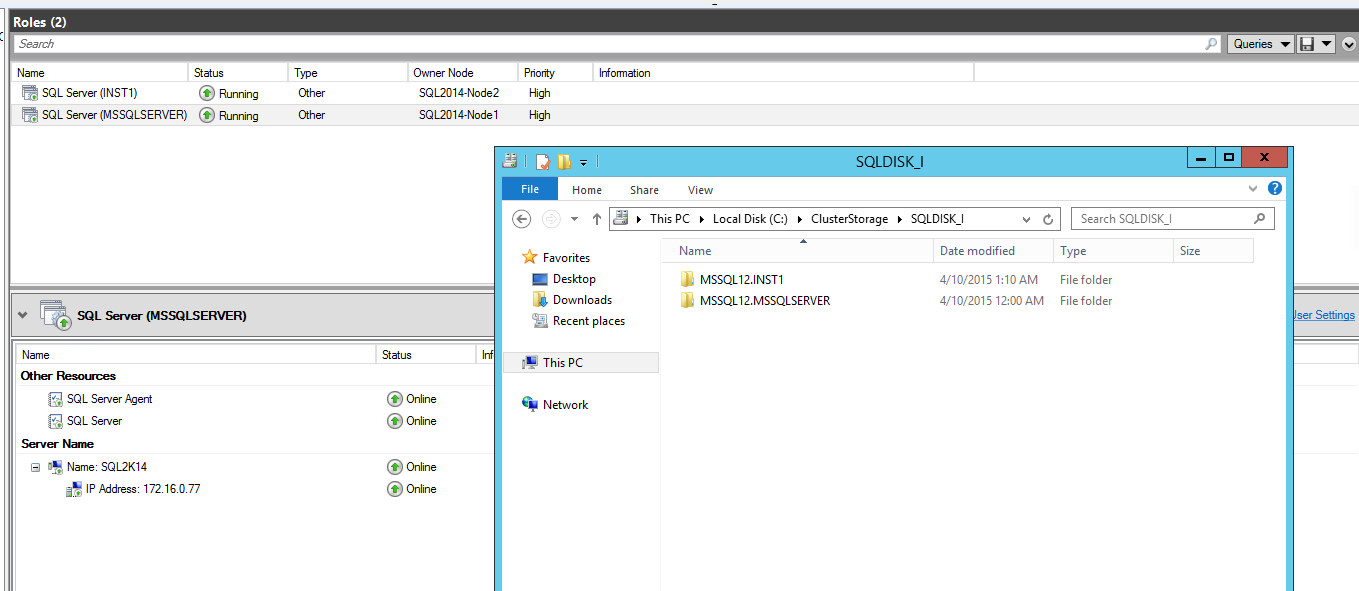
- Ease of storage management. In the past, if you want to provision shared storage for a SQL Server failover clustered instance, you would need to have it dedicated to that specific instance. This also means that if you want to add capacity, that capacity is locked in to the specific instance. This is one of the reasons why storage thin-provisioning is very common in the underlying SAN (aside from cost reasons, of course.) You also need to allocate a specific drive letter to the shared disk and be limited to the letters of the alphabet. Why do you think mountpoints became common with provisioning storage with failover clustered instances? But with CSVs, you can have multiple SQL Server failover clustered instances using the same volume. You can think of it in terms of multiple standalone SQL Server instances that have their databases in a single drive within the same machine. In the screenshot below, I have two SQL Server failover clustered instances – one using the default instance and one using a named instance. Take a look at the folder structure of the database files. Both instances are on the SAME shared storage (SQLDISK_J) running on top of a CSV, something that we could not do prior to CSVs.
CSVs have truly made shared storage what it really is in the context of SQL Server databases. As a SQL Server DBA, this, for me, is more than enough reason to upgrade to SQL Server 2014 (or higher) both from a high availability and ease of management points of view. And if you’re wondering about the cost of licensing, keep in mind that failover clustered instances are still supported on Standard Edition so long as you only have two nodes in your cluster.
Feeling helpless and confused when dealing with Windows Server Failover Clustering (WSFC) for your SQL Server databases?
You’re not alone. I’ve heard the same thing from thousands of SQL Server administrators throughout my entire career. These are just a few of them.
“How do I properly size the server, storage, network and all the AD settings which we do not have any control over?”
“I don’t quite understand how the Windows portion of the cluster operates and interacts with what SQL controls.”
“I’m unfamiliar with multi-site clustering.”
“Our servers are setup and configured by our parent company, so we don’t really get much experience with setting up Failover Clusters.“
If you feel the same way, then, this course is for you. It’s a simple and easy-to-understand way for you to learn and master how Windows Server Failover Clusters can keep your SQL Server databases highly available. Be confident in designing, building and managing SQL Server databases running on Windows Server Failover Clusters.
But don’t take my word for it. Here’s what my students have to say about the course.
“The techniques presented were very valuable, and used them the following week when I was paged on an issue.”
“Thanks again for giving me confidence and teaching all this stuff about failover clusters.”
“I’m so gladdddddd that I took this course!!”
“Now I got better knowledge to setup the Windows FC ENVIRONMENT (DC) for SQL Server FCI and AlwaysON.”
Please note: I reserve the right to delete comments that are offensive or off-topic.