A few days ago, one of my customers reached out to me on Yahoo Messenger (yes, it still exists) and asked how to identify what the potential data loss is when DBCC CHECKDB reports corruption of a SQL Server database. My common response is the usual “it depends” in that there are cases when DBCC CHECKDB may recommend using the option REPAIR_ALLOW_DATA_LOSS. And while you may be fine with doing so, it may not be supported. An example of this is a SharePoint database where Microsoft KB 841057 specifically mentions that using this option renders the database in an unsupported configuration. But say you have decided to proceed, how do you know what data potentially gets lost? This blog post walks you thru the process of identifying potential data loss when DBCC CHECKDB reports corruption in your SQL Server database.
- Thoroughly read the output from DBCC CHECKDB. DBCC CHECKDB gives you a ton of information to get you started. Kudos to the SQL Server team for providing such level of detail on the output of DBCC CHECKDB. When reading the output, note the following information
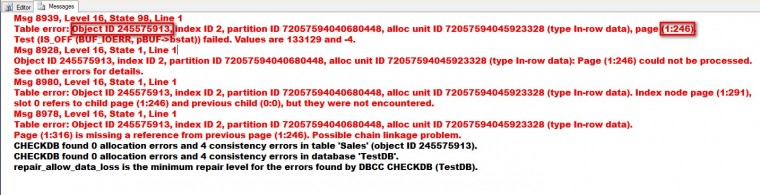
- Identify the object affected. This is a sample output of a corrupted database that I am playing around with. It’s one of the simplest example I can come up with to demonstrate how we can use the output of DBCC CHECKDB to identify the affected object. Note that DBCC CHECKDB did not recommend using the REPAIR_ALLOW_DATA_LOSS option for this case. We can look into that in future blog posts.
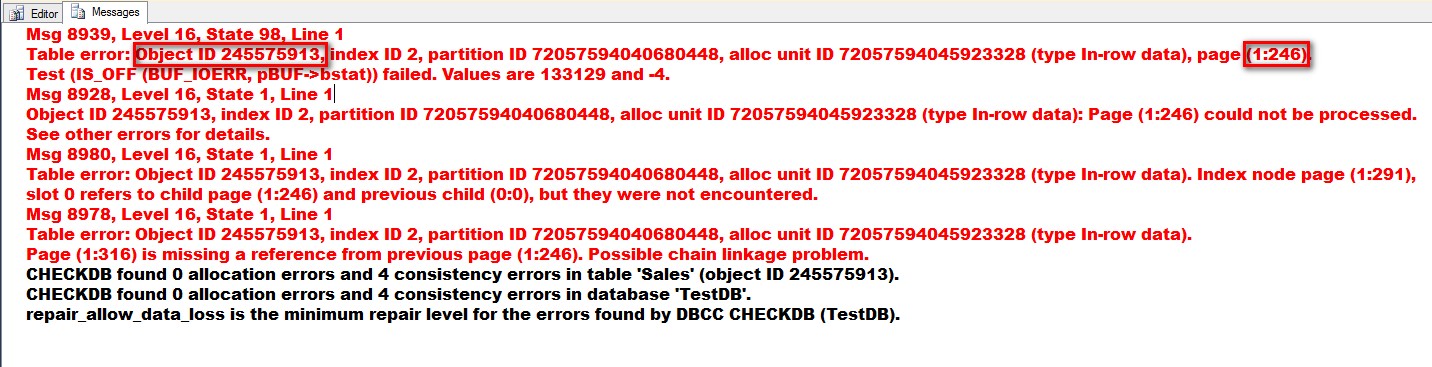 DBCC CHECKDB tells me that the affected object has an Object ID value of 245575913. I can use this information to find out the affected object.
DBCC CHECKDB tells me that the affected object has an Object ID value of 245575913. I can use this information to find out the affected object. From the result of the query, I know that my Sales table is affected by the corruption.
From the result of the query, I know that my Sales table is affected by the corruption. - Identify the affected page. Now that I know the affected object, I can decide whether or not the data is critical. As a data professional, I would consider ALL data as critical and would treat them the same. Of course, in reality, the business dictates whether or not data can be considered critical. Given the name of the table, let’s assume that this is considered critical data and would want to minimize data loss as much as we can. From the output of DBCC CHECKDB, we can see that the page 246 could not be processed – this is the corrupted page. It also tells me that page 291 (which is an index page) points to page 246 (the corrupted page) and that page 316 is missing a reference from the previous page (page 246.) It’s very helpful that everything we need to know about the corruption is available from the DBCC CHECKDB output. There is also something to note about the type of page that got corrupted. From the output, we know that it is an index page of type 2.
Table error: Object ID 245575913, index ID 2, partition ID 72057594040680448, alloc unit ID 72057594045923328 (type In-row data), page (1:246).
Referring to sys.indexes, we know that index ID value of type 2 means that the corrupted page is a non-clustered index. Since non-clustered indexes have structures that are separate from the data rows, we can safely say that we may not have any potential data loss at all.
- Decide how to resolve the corruption. Since we’ve already identified that the corrupted page is from a non-clustered index, we can opt not to restore form backup nor run repair using REPAIR_ALLOW_DATA_LOSS but simply disable and rebuild the index. Depending on how large the index is and the impact it has on the system, you can decide to either do it during or after production hours. Would it make sense to restore your database from the latest backup? Since we already know what the corrupted page is and what the potential data loss (in this case, no data loss at all,) restoring from backup wouldn’t make sense at all. Disabling and rebuilding the index is way better than taking your entire database offline just to fix a corrupted non-clustered index. Of course, if the output of DBCC CHECKDB told us something else – for example, an index ID value of type 1 which pertains to a clustered index – our decision on how to resolve the corruption would be a lot different than the example provided. And, as Paul Randal (Twitter | Blog) highlighted in his blog post, just because DBCC CHECKDB reported a bunch of errors doesn’t mean you have to take your database offline to fix it.
This is just one of the many ways to identify potential data loss when DBCC CHECKDB reports corruption. The more important thing here is to regularly check and monitor for database consistency so that you as the DBA get alerted immediately when it happens.
Please note: I reserve the right to delete comments that are offensive or off-topic.