SQL Server Failover Clustered Instances (FCI) and Availability Groups (AG) depend a lot on Windows Server Failover Clustering (WSFC). Understanding how the underlying WSFC platform works can help us maintain availability of our databases
Renting a car is something that I do quite frequently as I travel. Different rental car companies have a variety of car models – mostly newer ones with different features. The minute I get in my rental car, I spend 20 minutes getting myself familiar with the different basic features – turn signal lights, headlights, windshield wiper, motorized side mirrors, dashboard, etc. I, then, turn the ignition on and test the basic features that I just got myself familiarized with.
I don’t try out the car stereo nor the cruise control feature (I actually don’t use it, even on long drives) because I only need the car for one specific purpose – going from point A to point B. As far as I’m concerned, the voice commands that I can use to control my smart phone won’t matter if I cannot go from point A to point B.
Focus On The Main Goal
There’s a reason why you run SQL Server workloads – FCIs and AGs – on a WSFC. The reason is not to make your resume look good because you can manage a highly complex infrastructure (although it’s a natural side effect). Nor is it to improve your WSFC administration and troubleshooting skills. Again, it’s just another side effect.
The main reason why you are running SQL Server workloads on a WSFC is because you need high availability.
Any other reason is secondary.
Which brings up a very important point when troubleshooting database availability issues. The goal is always to bring the databases back online as quickly as you possibly can while meeting your recovery objectives (RPO/RTO) and service level agreements (SLA).
One of the things that I highlighted in my MSSQLTips article Force Start a Windows Server Failover Cluster without a Quorum to bring a SQL Server Failover Clustered Instance Online is to avoid the temptation to investigate the root cause while bringing the SQL Server FCI online. I just had to emphasize this fact before I even talk about my troubleshooting process.
Now, on with the process.
“Can You Hand Me The Manual?”
As I was driving back last week, I noticed a specific display on the rental car dashboard. The 2015 Chevy Cruze is showing Code 89. If I’m driving alone, I usually stop and review the manual to see what could be causing the issue. If I have passengers, I ask them to have a look at the manual to do the same.
Whether it’s a problem with the turn signal light or, in this case, the unknown dashboard information, I refer to the manual to find out what could have caused the issue. Further research revealed that Code 89 meant that the rental car is up for an oil change. Which means I don’t really have to worry too much about it because I’m about to return the car anyway and it won’t affect my drive back home.
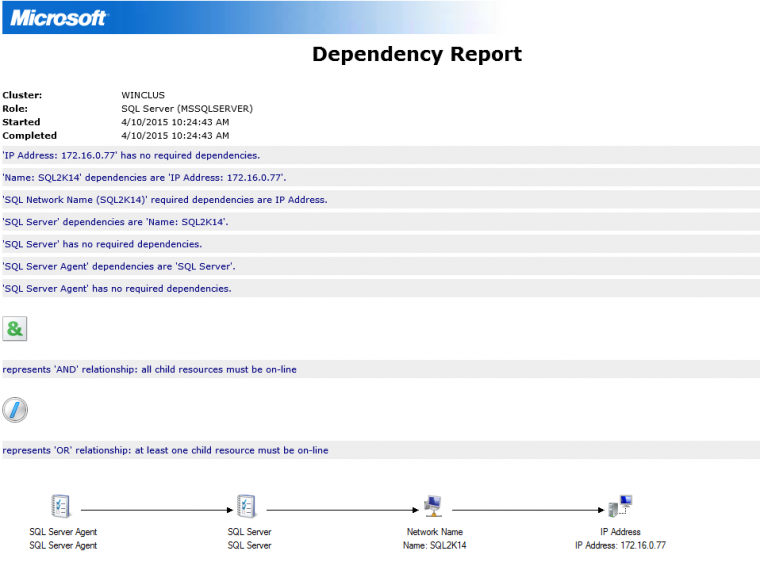
Any workload running on a WSFC has its own version of the manual: the Cluster Dependency Report. This report lists the dependencies between resources in a WSFC resource group.
The Cluster Dependency Report is a great tool to understand the dependencies between cluster resources within a group. It is highly recommended to print it out and include as part of your documentation prior to deploying your SQL Server FCI or AG to production. It will be very useful later on – as you will see in this blog post – when troubleshooting availability issues.
The Contents of the Cluster Dependency Report
One rainy afternoon after getting the car in the garage, I heard a continuous beeping sound even after taking the keys off the ignition. Its annoying. I wanted to get rid of it because it’s not normal. Referring to the manual, I realized that I have forgotten to turn off the headlights. If I don’t want to hear the continuous beeping sound, I first have to turn off the headlights before turning off the ignition.
In most cases, one clustered resource must be online before another resource can configure itself and start correctly. The second resource is said to “depend” on the other, just like how the beeping sound depends on the headlights being turned on after turning off the ignition. Similar to a standalone SQL Server instance, a SQL Server FCI and AG both have dependencies:
- The SQL Server Agent service depends on the SQL Server service
- The SQL Server service depends on the disk subsystem and the server name
- The server name depends on the IP address
Below is an example Cluster Dependency Report for a SQL Server FCI, one that I highlighted in a previous blog post.
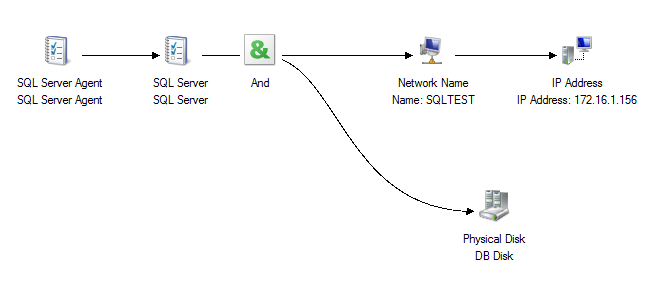
The AND Logic Dependency for High Availability
Looking at the Cluster Dependency Report, we can say that in order for the SQL Server clustered resource to remain online, both the shared drive/physical disk (DB Disk) AND the virtual network name (SQLTEST) should be online. Hence, the AND logic dependency – represented by the green & symbol. If either the shared drive/physical disk or the virtual network name is offline, rest assured that the SQL Server clustered resource will also be offline.
You need at least two clustered resources in order to see the AND logic dependency in action. In fact, in a SQL Server AG, you won’t see any AND logic dependencies within its own clustered resource group. If a listener name exists, the AG will be dependent on it. If not, availability of the AG will only depend on any factors affecting the availability of the WSFC (quorum) and the databases in the AG – database corruption, failed database drive, failed log file, etc.
The Dependency Hierarchy
The clustered resources without any dependencies will be the first ones to come online. Referring back to the same Cluster Dependency Report above, the virtual IP address (172.16.1.156) and the shared drive/physical disk (DB Disk) will be the first ones to come online because they don’t have to wait on anything. However, to bring the SQL Server Agent online, it has to wait for the SQL Server clustered resource to come online, the virtual network name (SQLTEST) and the shared drive/physical disk (DB Disk) to both come online and, consequently, the virtual IP address (172.16.1.156) to come online. Given the dependency hierarchy, the SQL Server Agent is the last one in the group to come online.
Also, based on the dependency hierarchy, we can simply say that the amount of time to bring our databases online is very much dependent on the following:
- how quickly the shared drive/physical disk (DB Disk) AND the virtual network name (SQLTEST) can come online
- how quickly Active Directory domain services (ADDS) can respond to checking the virtual network name (not shown on the Cluster Dependency Report)
- how quickly DNS can resolve the virtual IP address (also not shown on the Cluster Dependency Report)
What Could Be The Problem?
Given what you know now about the Cluster Dependency Report, try to answer the question below. Post your response and explanation in the Comments section.
NOTE: You don’t need to have a Facebook account to comment. And, please don’t try to select your answers by clicking on the checkboxes. The whole section below is an image. You need to type your answer and explanation in the Comments section.

Additional Resources
- Microsoft KB article 171791: Explanation of Dependencies in Microsoft Cluster Server and Windows Server Failover Clustering
- Microsoft KB article 835185: Failover cluster resource dependencies in SQL Server
Thank you Edwin for nice explanation !
As SQL Server Service is not dependent on SQL Server Agent, so it would be ONLINE when SQL Server Agent clustered resource goes offline. My answer would be #1,#2,#3 & #5.
Thanks for your comment, Anil.
I totally agree with Anil
Thanks for your comment, Hoang.
I wish taking tests in schools are as simple as this 🙂