This is a very common question that gets asked on the technical forums, newsgroups, social media, etc. when it comes to synchronous SQL Server Always On Availability Groups (AG): “Why did my AG not automatically failover?” Notice that I mentioned SYNCHRONOUS and not asynchronous. Only when Always On Availability Group replica databases are configured for synchronous commit can automatic failover happen. Also, there can only be two (not three nor four, only two) synchronous replicas configured in order for automatic failover to occur. And both of them NEED to be configured with automatic failover. That is because of the fact that the Windows Server Failover Cluster (WSFC) has to decide which replica to move the load to should failure occurs. Imagine the role of a quarterback in American football. He only has one ball to pass (the Always On Availability Group) and he needs to decide who gets to catch the ball to continue the game. He can’t possibly throw the ball to two of his other team mates and expect both of them to catch it without causing them to fumble.
But even when everything on the Always On Availability Group is configured properly, there are cases when the AG does not automatically failover to the synchronous replica partner. Here are the three common reasons that prevent that from happening. To make it easier to remember, let’s use the acronym S.P.A. so you can include it in your checklist:
- Synchronous Status. Note that synchronous Always On Availability Group replicas are required to ensure automatic failover. This means that, at any given point in time, the AG replica databases can be out-of-sync. There could be a number of reasons why your AG replicas fall out-of-sync: network glitch, AG is suspended or paused, replica becomes temporarily unavailable, massive amounts of transaction log records that couldn’t commit, etc. When the AG replicas are out-of-sync, automatic failover does not happen. One important thing that a lot of SQL Server DBAs miss out on is this: it’s the database that dictates the status of the entire replica. It means that even if you have only 1 out of 10 databases that is out-of-sync, the entire replica is out-of-sync. So, you need to decide how to group your databases together in order to achieve synchronized state across all of the databases in the AG replica. Use the T-SQL query below to check if there is one or more databases in your AG that could prevent automatic failover. You need to have a value of 1 for all of the databases in your AG replica. More importantly, you need to constantly monitor if the synchronous AG replicas are going out-of-sync.
SELECT database_name, is_failover_ready
FROM sys.dm_hadr_database_replica_cluster_states
WHERE replica_id IN
(SELECT replica_id
FROM sys.dm_hadr_availability_replica_states)
- Permissions. Because Always On Availability Groups run on top of a Windows Server Failover Cluster, the WSFC uses the SQL Server cluster resource DLL to connect to the SQL Server instance for health detection. The WSFC uses the account NT AUTHORITY\SYSTEM (or whatever you used for the Cluster service) to connect to the SQL Server instance. In order for the WSFC to perform health and failure detection, the account NT AUTHORITY\SYSTEM needs to be granted the appropriate permissions on all of the SQL Server instances that are configured for AG replica automatic failover. I’ve seen others simply grant the account sysadmin privileges but that’s just way too much privileges for what it simply needs. I’m a bit paranoid when it comes to security so I only grant it the necessary permissions it needs: Alter Any Always On Availability Group, Connect SQL and VIEW SERVER STATE. Use the T-SQL query below to grant the account NT AUTHORITY\SYSTEM the appropriate permissions.
USE [master]
GO
CREATE LOGIN [NT AUTHORITY\SYSTEM] FROM WINDOWS WITH DEFAULT_DATABASE=[master],
GO
GRANT ALTER ANY AVAILABILITY GROUP TO [NT AUTHORITY\SYSTEM]
GO
GRANT CONNECT SQL TO [NT AUTHORITY\SYSTEM]
GO
GRANT VIEW SERVER STATE TO [NT AUTHORITY\SYSTEM]
GO
- Allowable Failure. I would assume that you’ve tested automatic failover with your AG replicas immediately after configuration. I also bet that you actually enjoyed doing it and tried doing so a couple of times until you noticed that it only worked the first few times and then it didn’t. Well, let me break it up to you: that’s just how it works. Always On Availability Groups are created as a WSFC cluster resource group. A cluster resource group will have its own properties, one of which is called Maximum failures in the specified period. There’s a reason why it is named as such. This is the maximum allowable failures for the cluster resource group (or Always On Availability Group, in this case) to automatically failover to any of the synchronous AG replicas. If you’ve maxed out this threshold, then, automatic failover will no longer occur. The default value for this property is 1 automatic failover for every 6 hours. Refer to the screenshot below for this property value.
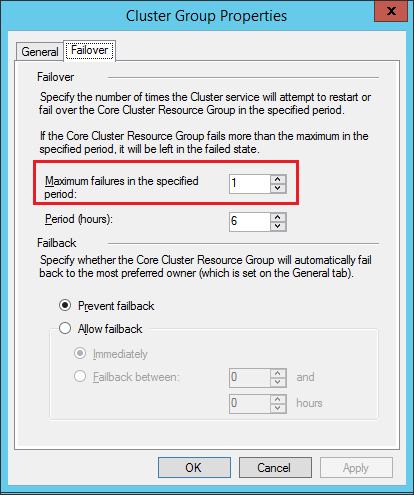
For testing purposes, it is recommended to increase this value to make sure that you get the expected behavior, that is automatic failover. After the test, set it back to the default values. There are several arguments about the appropriate value for this property but my rule-of-thumb is to use the default value but monitor properly. If the AG (or any cluster resource group running on the WSFC) automatically fails over to the synchronous replica, you don’t just sit back and relax thinking that the solution worked as expected. You need to investigate immediately why the failover occurred to avoid potential downtime. The only way to immediately respond is to be notified when it happens thru monitoring.
So, when your Always On Availability Group replica does not automatically failover, you might want to give it the S.P.A. treatment. Better yet, why not do it right now. Stop what you’re doing and check your synchronous AG replicas. You don’t want to be caught off-guard and experience downtime on your mission-critical databases when you’ve spent that much money and effort implementing it.
Additional Resources:
- Troubleshooting automatic failover problems in SQL Server 2012 AlwaysOn environments
- Failover cluster resource recovery behavior in Windows Server 2008 (also applies to Windows Server 2012 and higher)
- Flexible Failover Policy for Automatic Failover of an Always On Availability Group (SQL Server)
Feeling helpless and confused when dealing with Windows Server Failover Clustering (WSFC) for your SQL Server databases?
You’re not alone. I’ve heard the same thing from thousands of SQL Server administrators throughout my entire career. These are just a few of them.
“How do I properly size the server, storage, network and all the AD settings which we do not have any control over?”
“I don’t quite understand how the Windows portion of the cluster operates and interacts with what SQL controls.”
“I’m unfamiliar with multi-site clustering.”
“Our servers are setup and configured by our parent company, so we don’t really get much experience with setting up Failover Clusters.“
If you feel the same way, then, this course is for you. It’s a simple and easy-to-understand way for you to learn and master how Windows Server Failover Clusters can keep your SQL Server databases highly available. Be confident in designing, building and managing SQL Server databases running on Windows Server Failover Clusters.
But don’t take my word for it. Here’s what my students have to say about the course.
“The techniques presented were very valuable, and used them the following week when I was paged on an issue.”
“Thanks again for giving me confidence and teaching all this stuff about failover clusters.”
“I’m so gladdddddd that I took this course!!”
“Now I got better knowledge to setup the Windows FC ENVIRONMENT (DC) for SQL Server FCI and AlwaysON.”
Please note: I reserve the right to delete comments that are offensive or off-topic.