“During one of my SQL Server Index Internals presentation, an attendee asked me how filtered indexes look like and if they are stored exactly the way the traditional indexes are. I was tempted to show the internals of how filtered indexes looked like using DBCC PAGE during the presentation but held back because it deserves its own blog post. “
Whenever I do my SQL Server index internals presentation, I show the attendees how to navigate thru the index structure to find the record (or records) retrieved in a query. I start by using the undocumented command DBCC IND to analyze the index structure for a particular index – clustered or non-clustered. I, then, use the page numbers returned by DBCC IND to navigate to the index structure using DBCC PAGE. As an example, I’ll use the [Sales].[SalesOrderDetail] table in the AdventureWorks database. What I did was to copy the contents of the [Sales].[SalesOrderDetail] table in another database to simplify my queries and eliminate the Sales schema in the name.
The original [Sales].[SalesOrderDetail] table has a clustered index defined on the SalesOrderID and SalesOrderDetailID columns.
USE SampleDB
GO
SELECT name, index_id FROM sys.indexes
WHERE OBJECT_ID = (SELECT OBJECT_ID FROM sys.objects WHERE name = 'SalesOrderDetail')
GO
sp_helpindex 'SalesOrderDetail'

I grab the index id value of the index that I want to analyze and use it in my DBCC IND command. In this case, the clustered index id value is 1 (since you can only have one clustered index per table, rest assured that the index id value of all clustered indexes in all of your tables will be 1.)
DBCC IND (SampleDB, SalesOrderDetail, 1)
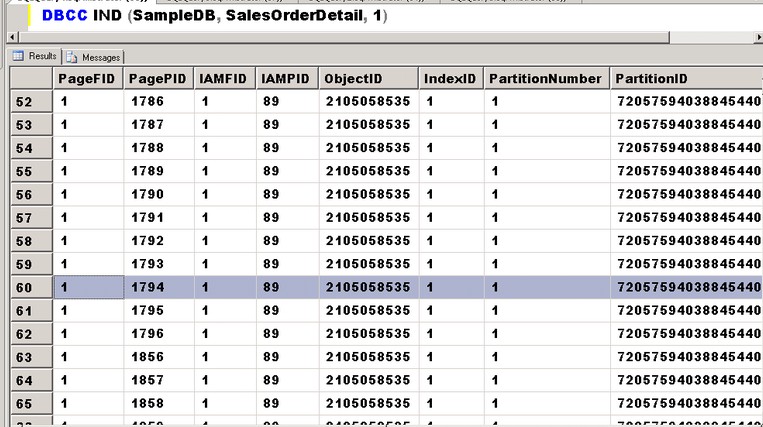
The output of DBCC IND displays a lot of information but what I’m more concerned about are these two: the level of the page in the index structure and its corresponding page number. The highest level in the index structure is the root page and is the starting point of the navigation in the index structure. Now, if you look closely on the output of DBCC IND, only the page numbers in the PagePID column are in increasing order. If you want to know the highest level in the index structure, you need to either store the results of DBCC IND in a table that you can sort by column. Or, if you’re like me who likes Excel a lot, you can just copy-and-paste the results in Excel and sort by the index level column. Having already done that, I’ll use DBCC PAGE to display information about my root page – in this case, page 1794. I’m using the trace flag 3604 to send the output of DBCC PAGE to SQL Server Management Studio.
DBCC TRACEON (3604)
GO
DBCC PAGE (SampleDB, 1, 1794, 3) -- page id of the root page
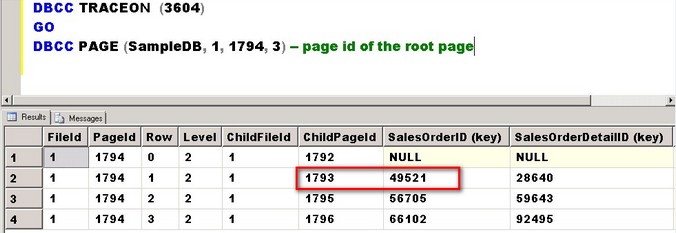
(A more detailed description of using the DBCC PAGE command can be found in this a bit outdated (but still relevant) Microsoft KB article. Paul Randal, CEO of SQLSkills.com and former Program Manager on the SQL Server product team, also blogged about using both DBCC IND and DBCC PAGE.)
The page number that I will check next will depend on the query that I run. If my query requires a SalesOrderID value of 50105 (for example, SELECT CarrierTrackingNumber, ModifiedDate FROM SalesOrderDetail where SalesOrderID=50105,) I will look at the page number that contains this index key value since the SalesOrderDetail column is included my clustered index definition. From the screenshot, that page number is 1793. The index key value contains the lower boundary of the values contained in the index page. I’ll use that page number in my next run of the DBCC PAGE command.
DBCC TRACEON (3604)
GO
DBCC PAGE (SampleDB, 1, 1793, 3)-- page id of the page containing SalesOrderID=50105
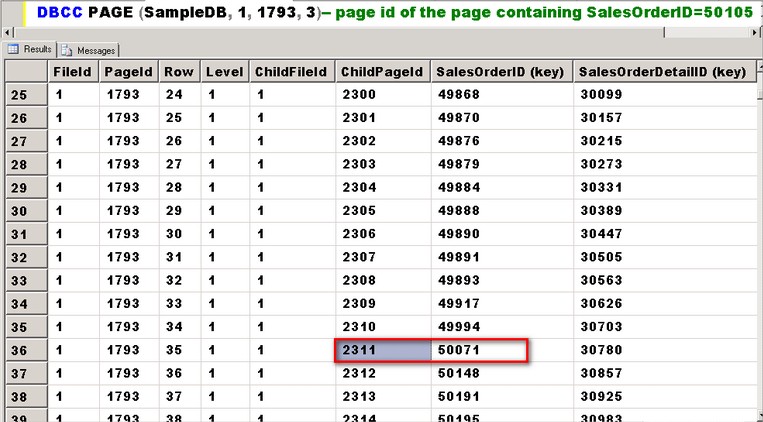
If you pay close attention to the results of the DBCC PAGE command, the previous run is still at level 1. This means that we are still at the non-leaf level of the index structure. We still need to go down another level – level 0 – to retrieve the two other columns that we need – CarrierTrackingNumber and ModifiedDate – since these two columns are not included in the index definition. Using the same process that we did in the previous run of the DBCC PAGE command, we’ll grab the page number that contains the index key value of the SalesOrderDetail column equal to 50105. From the screenshot, that page number is 2311.
DBCC TRACEON (3604)
GO
DBCC PAGE (SampleDB, 1, 2311, 3)-- page id of the page containing SalesOrderID=50105
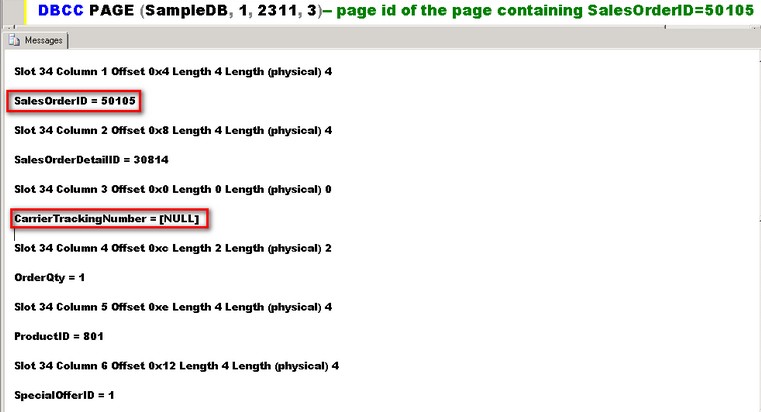
From the screenshot, you’ll see the contents of the data page. Since a clustered index contains the table itself, the leaf-level of the clustered index contains all of the other columns and their corresponding data. And, since we’re already at the lowest level of the index structure, this page is where the data is stored.
The way I used DBCC IND and DBCC PAGE to navigate thru the index structure is how SQL Server uses indexes to retrieve the records required by your query. Of course, there are other factors that influence query performance like statistics and index fragmentation. This is just the ideal way that SQL Server uses the index structure to retrieve records from the data pages.
Now, you might be asking, “Isn’t this blog post about filtered indexes and how they look like? How come I don’t see any discussion about filtered indexes?” Well, you’re absolutely right. That’s because in order to understand how filtered indexes look like, we need to understand how the index structure looks like and how SQL Server uses the index structure to navigate to the records that we retrieve from our queries. I just used clustered indexes as an introduction. Now, what are filtered indexes? Introduced in SQL Server 2008, filtered indexes are a type of non-clustered indexes that contain a subset of data. Think of it this way: a non-clustered index contains a record for each row in your table while a filtered index is a non-clustered index with a WHERE clause. This means that a filtered index requires less storage space thereby resulting in improved query performance and reduced index maintenance costs.
As an example, I will create two non-clustered indexes on the SalesOrderDetail table using the ModifiedDate column. The first index will be your traditional non-clustered index while the second one is a filtered index.
USE [SampleDB]
GO
--traditional non-clustered index
CREATE NONCLUSTERED INDEX [IX_SalesOrderDetail_ModifiedDate] ON [SalesOrderDetail]
(
[ModifiedDate] ASC
)
GO
-- filtered index: non clustered index with a WHERE clause
CREATE NONCLUSTERED INDEX [IX_SalesOrderDetail_ModifiedDate_Filtered] ON [SalesOrderDetail]
(
[ModifiedDate]
)
WHERE ModifiedDate>'2004-01-01'
GO
In part 2 of this blog post, we will look at how filtered indexes look like from a storage perspective and compare them with the traditional non-clustered indexes. Stay tuned.
Please note: I reserve the right to delete comments that are offensive or off-topic.