
As my son was struggling to figure out how to download the Amazon Kindle app on his iPad, I can’t help but notice the email he got from Amazon. The email contains the URL link where to download the Kindle app. And the message said something like this:
No wonder he can’t get it to work. The link that he was downloading was specifically for an Android device, not for iOS. And he’s already spent two hours trying to figure out why.
Reading the Fineprint
In today’s fast-paced lifestyle where we glance at social media posts like skimming thru the morning newspaper, we are tempted to get something done fast and skip thru the details. Sure, IT’s fast-paced environment requires us to learn new things and get something done ASAP. Why do you think the expression RTFM exists?
Take, for instance, a clustered resource in a SQL Server failover clustered instance (FCI.) If you’re familiar with how the different cluster resources in a SQL Server FCI depend on each other, you would know that the virtual network name is dependent on the virtual IP address.

That means the virtual IP address needs to first come online before the virtual network name can come online. If you try to bring the virtual network name online but failed, you know that the issue could potentially be the virtual IP address.
Now there are several different reasons why the virtual IP address won’t come online – IP address conflict in the network, the DHCP server (if you are using DHCP-assigned IP address) is unavailable, maybe the DNS server is offline, etc. Knowing this, you can easily go down the rabbit hole and check any network-related issue that you can think of that could possibly be preventing the virtual IP address from being brought online. The more time you spend on trying to figure out the issue, the longer your downtime becomes. Keep in mind that the SQL Server FCI is offline while you’re doing this and your databases unavailable.
What Does The Fineprint Say?
I had the opportunity to deal with a similar issue – a SQL Server FCI that won’t come online due to an issue with a virtual IP address. And I did end up wasting time trying to figure out why the virtual IP address wouldn’t come online. Until I decided to read the error log.
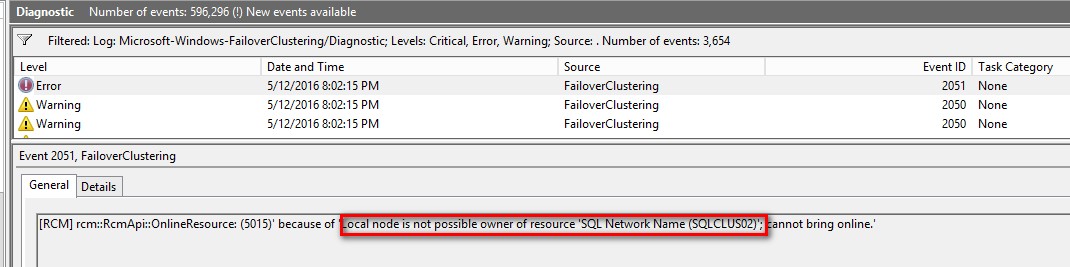
The Windows Server Failover Cluster (WSFC) had three (3) nodes – two for high availability (HA) and one for disaster recovery (DR.) One of the nodes failed causing the WSFC to move all of the clustered resource groups to the other node used for HA. All of the SQL Server FCIs running on the WSFC were successfully brought online – except for one. And I wasted an hour trying to bring it back online simply because I didn’t pay attention to what the error message was saying.
Clustered Resource-level Policies in Action
I categorize policies that apply to resources in a WSFC in two – resource group-level and resource-level. Any policies applied to the resource group-level affects all of the clustered resources within that group. Resource-level policies only apply to the specific clustered resource but may affect the behavior of the entire resource group. This was what is preventing the virtual IP address from being brought online – not any network-related issue.
One of the resource-level policies available to any clustered resource refers to the Possible Owner. This policy is set in the <Resource> Properties: Advanced Policies tab of the clustered resource. This policy defines which of the available nodes in the WSFC can host the clustered resource. Take a look at the Possible Owner policy of the virtual IP address for the affected SQL Server FCI.
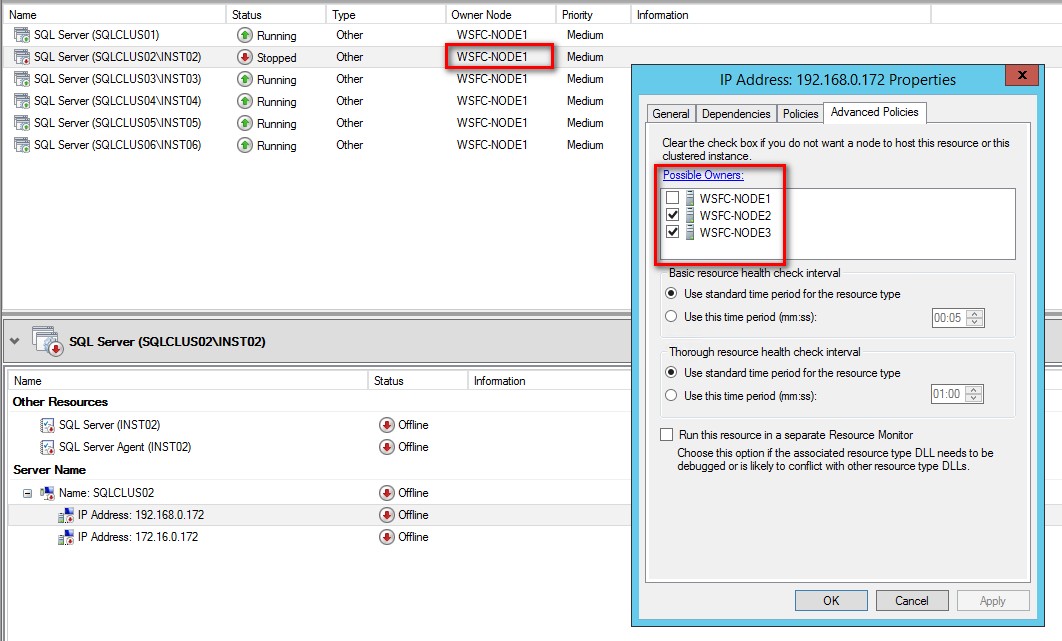
Somebody accidentally removed WSFC-NODE1 from the list of Possible Owners. And guess where I was trying to bring the SQL Server FCI online? On WSFC-NODE1. So, all this time, it was the policy that is preventing the virtual IP address to come online, not anything network-related. And I wasted time and effort trying to figure it out because I wasn’t paying attention to the detail specified in the error log. Good thing that this was a test environment and not a production one or I would have blown past the service level agreement. All I did after that was to add WSFC-NODE1 back to the list of Possible Owners and managed to bring it online.
Pay Attention To Detail
This is just one example of how attention to detail can help make your systems highly available. I bet you have stories of your own about how you managed to prevent an outage (or probably caused one) because of a small detail that you noticed (or ignored.) I’d love to hear about it in the Comments section.
Feeling helpless and confused when dealing with Windows Server Failover Clustering (WSFC) for your SQL Server databases?
You’re not alone. I’ve heard the same thing from thousands of SQL Server administrators throughout my entire career. These are just a few of them.
“How do I properly size the server, storage, network and all the AD settings which we do not have any control over?”
“I don’t quite understand how the Windows portion of the cluster operates and interacts with what SQL controls.”
“I’m unfamiliar with multi-site clustering.”
“Our servers are setup and configured by our parent company, so we don’t really get much experience with setting up Failover Clusters.“
If you feel the same way, then, this course is for you. It’s a simple and easy-to-understand way for you to learn and master how Windows Server Failover Clusters can keep your SQL Server databases highly available. Be confident in designing, building and managing SQL Server databases running on Windows Server Failover Clusters.
But don’t take my word for it. Here’s what my students have to say about the course.
“The techniques presented were very valuable, and used them the following week when I was paged on an issue.”
“Thanks again for giving me confidence and teaching all this stuff about failover clusters.”
“I’m so gladdddddd that I took this course!!”
“Now I got better knowledge to setup the Windows FC ENVIRONMENT (DC) for SQL Server FCI and AlwaysON.”
Please note: I reserve the right to delete comments that are offensive or off-topic.