Last week, I wrote about a database corruption case that I had the opportunity to work on. I spent a fair amount of time on the phone with the database developer to understand what the columns are for, what their values represent and the corresponding relationships with other tables. In the process of trying to recover as much data as I possibly can, I noticed a few key ideas that I believe database developers should be aware of when designing databases.
When Functionality Isn’t Enough
I was a former developer. I wrote Visual Basic, VB.NET, ASP.NET, C# and Java code. I gave up that life almost 7 years ago when I realized that I was losing a lot of hair. I still write PowerShell and T-SQL code today but it’s not the same as when I was just a hard-core developer.
With tight deadlines and features to release, the main goal of a developer is to “make something work” in preparation for release. That mindset is still prevalent in today’s development and programming culture. In fact, if you look at developer test cases, most of the things that are tested are focused on functionality. Bugs fixes are prioritized based on features that have the highest impact to customers or end users. And there’s nothing wrong with that. The goal is to ship features as quickly as possible.
And then the application grows. What used to be a small application used by 25 users now becomes mission-critical. Performance start to matter. We throw in more hardware resources. Or move it to a virtualized platform so we can easily add more resources. We make it highly available – put it in a cluster or on a load balancer – anything to minimize downtime while making it fast.
Does this sound familiar? Notice that everything done to the database at this point are all external. The rationale – development time is more expensive than hardware nowadays. So we don’t go back to the drawing board to redesign the application to scale. Adding a new column to a table is done because of a new feature request, not because we want to make it scalable and highly available. And I have been having this discussion with developers for years now. It’s not that they can’t do anything about it. It’s just that the organization’s priorities are more inclined towards selling more features.
Data Types and Storage Structures Do Matter in HA/DR
I previously wrote about how data types affect HA/DR where I gave an example of how a simple data type change reduced the amount of transaction log records generated for a transaction. As I was working on this data recovery issue, I noticed a corrupted page that prevented me from querying for ranges that I can use to extract the records. For example, if I have 100 records in my table that consist of 4 pages and page 3 is corrupt, I need to know what records are in pages 1, 2 and 4 in order to recover as much data as I can.
Now, this is easier said than done because we need to know how the records in the table are stored on the page. I’ll use the sample code that SQL Server MVP and SQLSkills CEO Paul Randal (Twitter | Blog) provided in his blog post.
CREATE DATABASE [SampleDB];
GO
USE [SampleDB];
GO
CREATE TABLE [SampleTable] (
[c1] INT,
[c2] UNIQUEIDENTIFIER DEFAULT NEWID (),
[c3] CHAR (4100) DEFAULT ‘a’);
GO
CREATE CLUSTERED INDEX [SampleTable_cl] ON [SampleTable] ([c1], [c2]);
GO
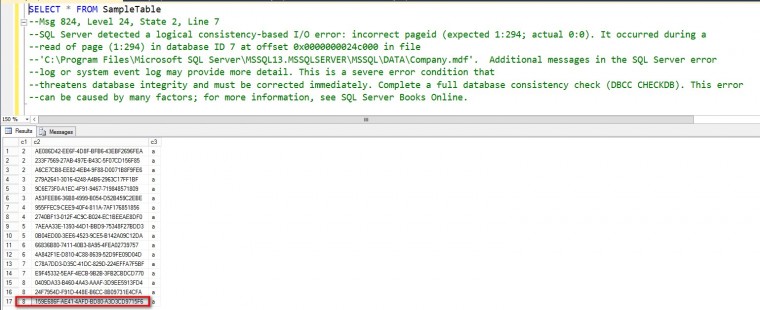
The table has a defined clustered index; the records on the page will be sorted according to the clustered index key. The clustered index key consists of two columns – the INT column and the UNIQUEIDENTIFIER column. Now, we all (I would assume) know how to count numbers and understand that the numbers will be sorted in ascending order. So, looking at the table, the records will first be sorted by the INT column first. If there are duplicates in the INT column, the records will then be sorted by the UNIQUEIDENTIFIER column, as shown below
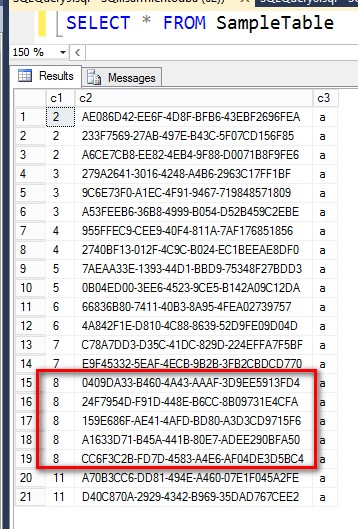
I’ll go back to my simple example earlier. If I have 100 records in this table that consist of 4 pages and page 3 is corrupt, I need to know what records are in pages 1, 2 and 4 in order to recover as much data as I can. One way to identify the range of records to recover is run a SELECT * FROM [tablename] to identify the first corrupted page and a SELECT * FROM [tablename] ORDER BY [clustered_index_key] DESC to identify the last corrupted page. Anything before and after those ranges can be recovered. Then we will have to see the last record returned before the corrupted page, like in the example below.
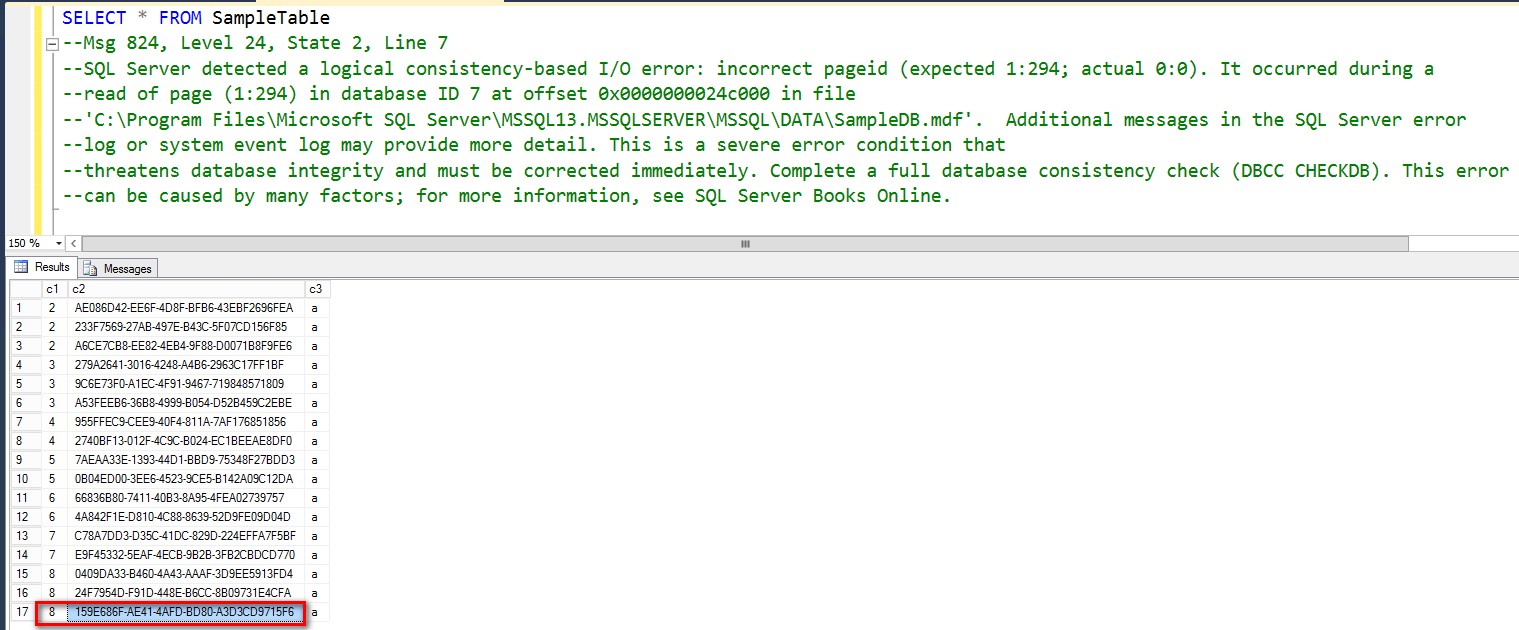
In order to find what other records we can recover from the start of the corrupted page to the end, we need to navigate thru the B-tree to generate the range queries. Do we just say, “so long as it satisfies [c1] >=8” to find those rows? Nope. We need to look at the next column in the clustered index key – the UNIQUEIDENTIFIER column.
Have you ever wondered how SQL Server sorts GUID columns? The reason why we need to understand how SQL Server does so is because when you use GUID values – like the UNIQUEIDENTIFIER column – in your clustered index key, it factors into how you would write your range queries. In my case, I need to know in order to write the appropriate range queries to recover as much data as I possibly can. Here’s a blog post from almost 10 years ago explaining the algorithm about how GUID values are compared in SQL Server 2005. The concepts apply up to the latest version of SQL Server. Basically, the GUID values are evaluated from right-to-left in terms of byte-groups and left-to-right within that group.
The bottom line is that not only are you using up a lot of storage space on a data page for using GUID values in your clustered index key (which also ends up on all of the non-clustered index key) that increases the size of the database, you are also influencing the range queries that need to be written in case you need to recover as much data as you can when database corruption happens. Those affect how quickly can you restore your database and how much data you can recover.
Design With Intent
Whether you are working on a new database application or maintaining an existing one, remember to keep the S.P.A. – security, performance and availability – in mind. Keeping that mindset will help you become a better data platform architect as you move along in your career. Your database applications will also survive the things that we hope not to encounter on a regular basis – DISASTERS.
Additional Resources
- The Case Against SQL Server VSS- or Virtualization-Based Backups
- Data Types and How They Affect HA/DR
- Data Types and How They Affect Database Performance
- How are GUIDs compared in SQL Server 2005?
- Regularly Treat Your Databases to a S.P.A.
Please note: I reserve the right to delete comments that are offensive or off-topic.